Background & Motivation
Large language models (LLMs) have shown strong performance across diverse financial tasks, yet portfolio management (PM) remains poorly benchmarked. Existing benchmarks ignore cross-asset correlation structures and fail to evaluate the complete PM decision pipeline, missing the compounding errors that arise as reasoning propagates through sequential allocation stages.
We introduce PortBench with the following key contributions:
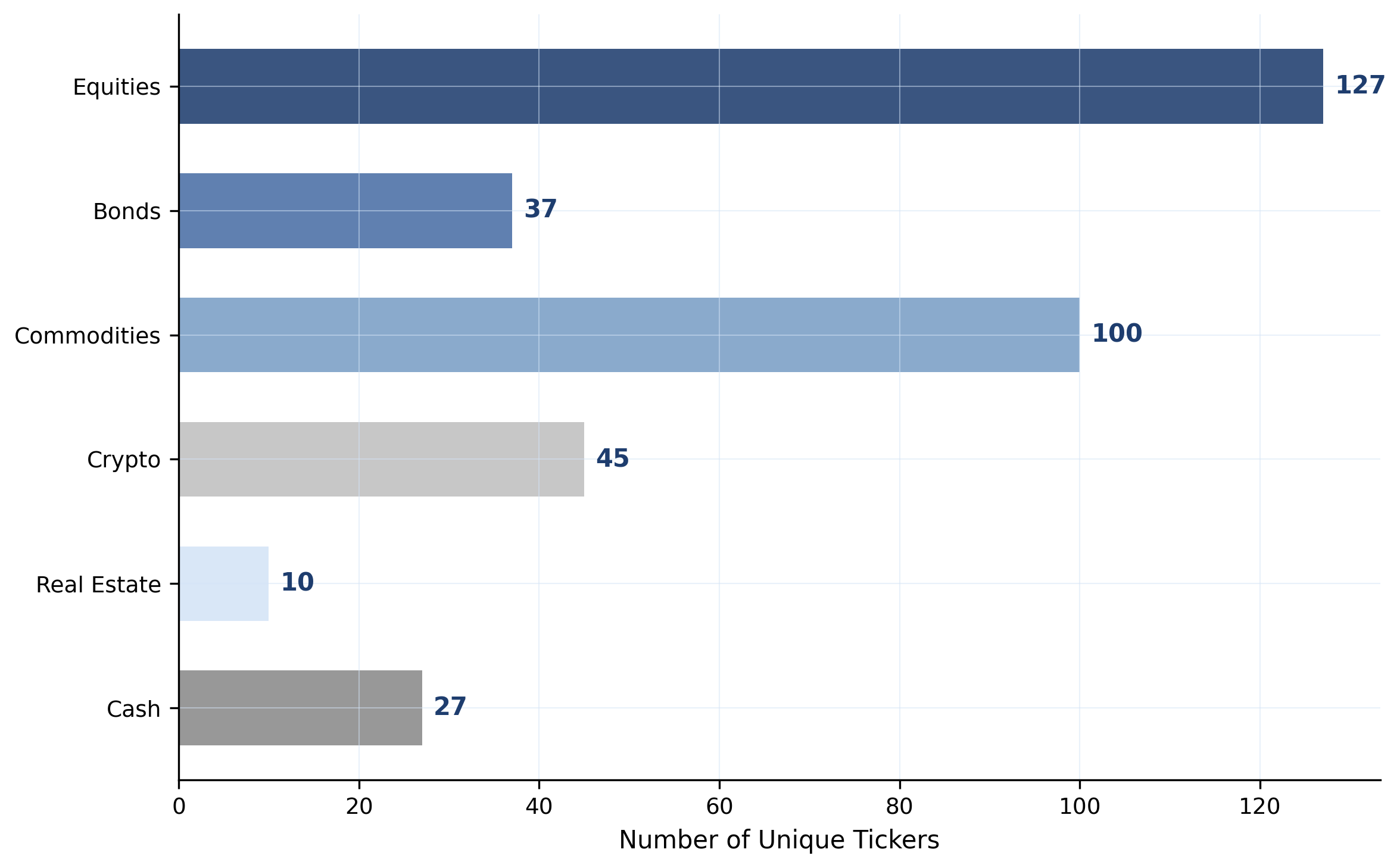
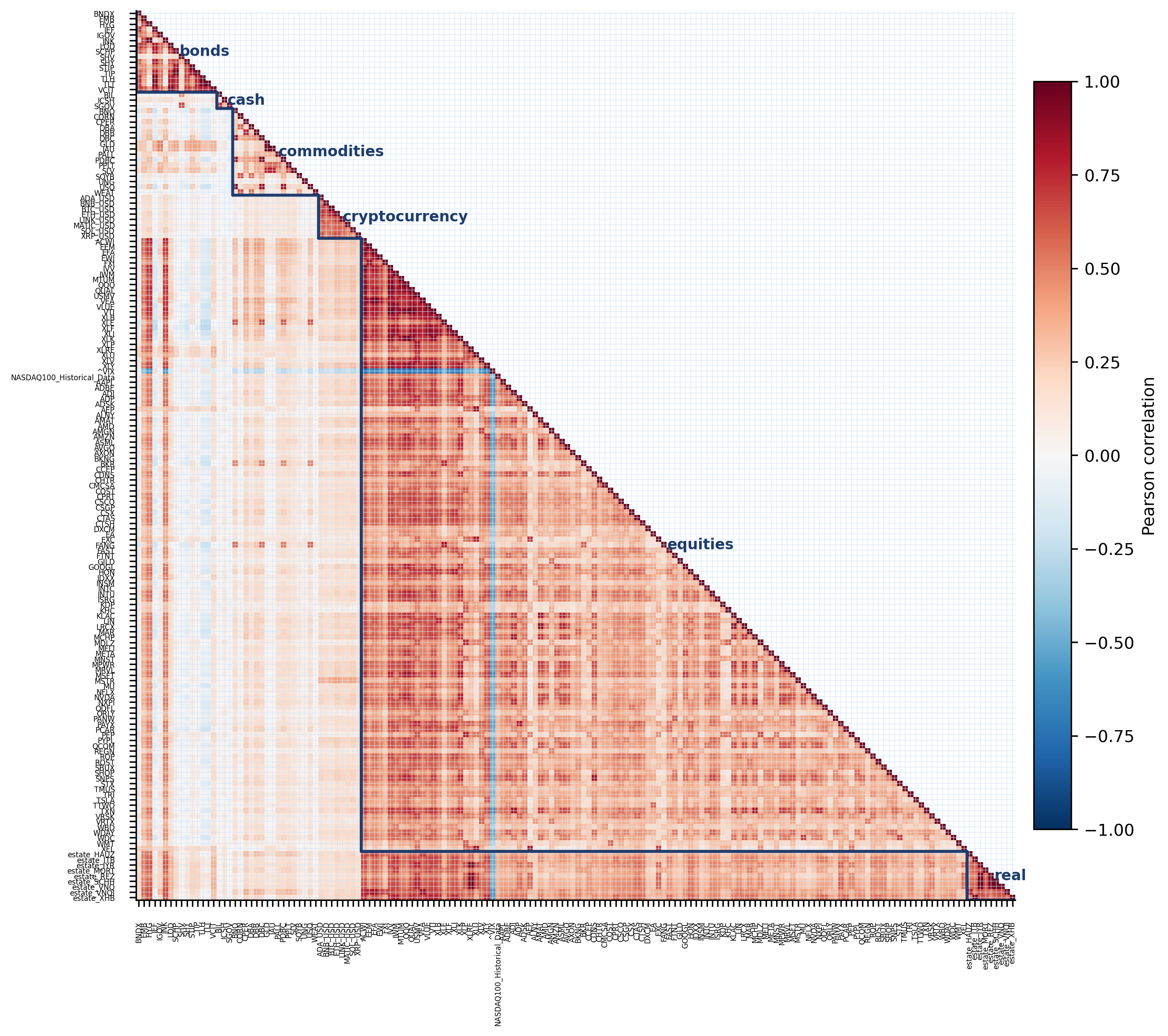
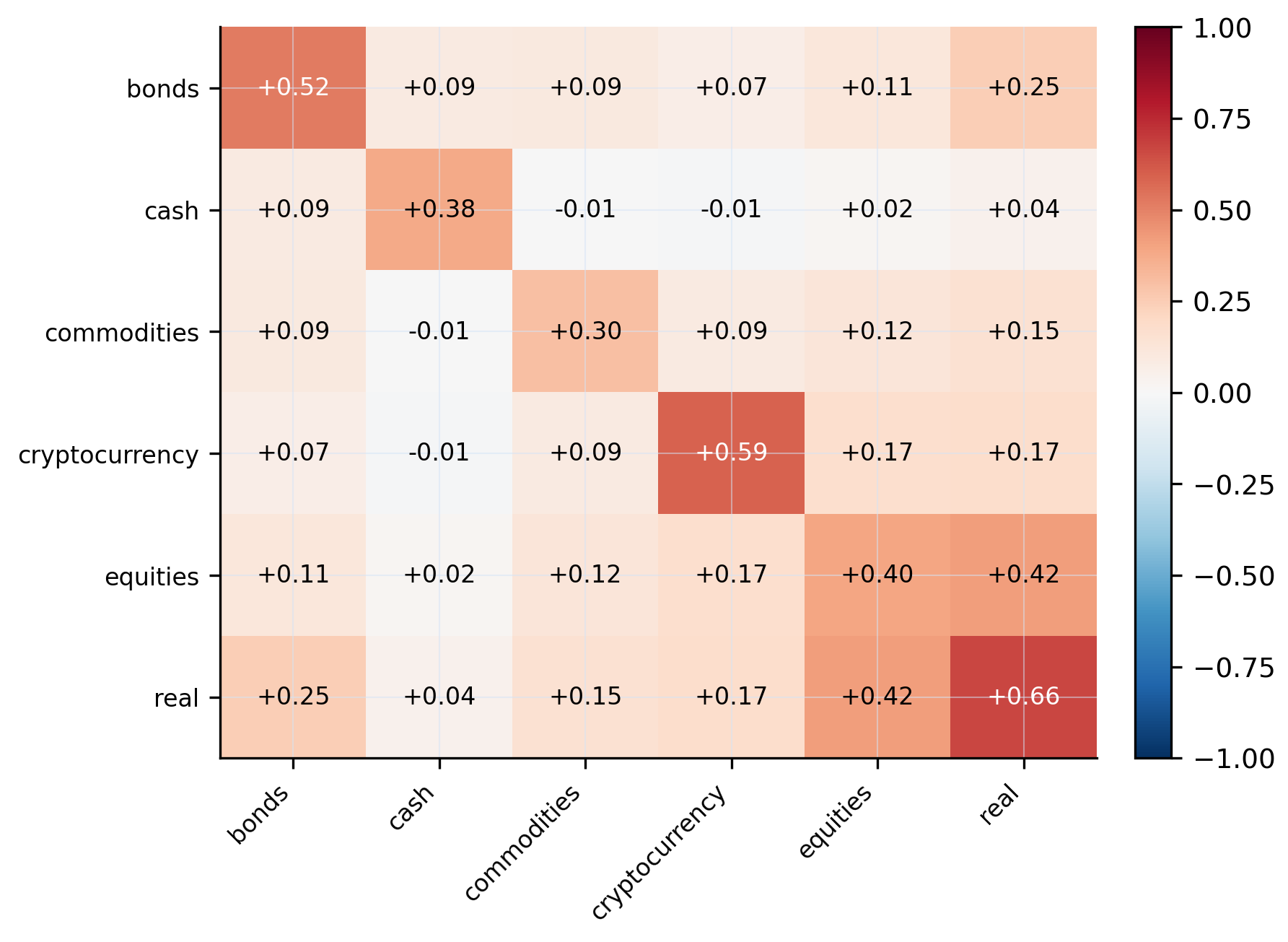
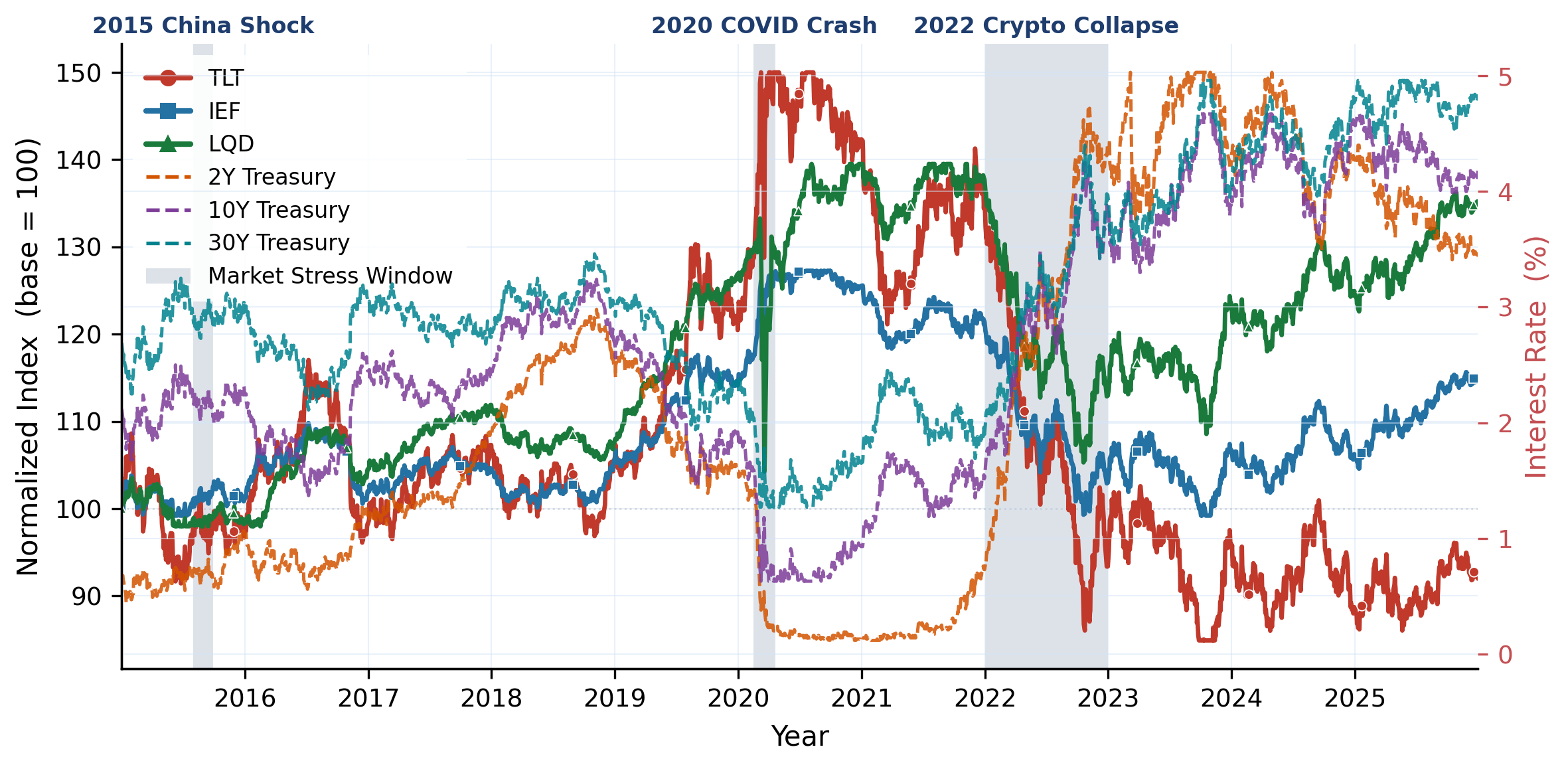
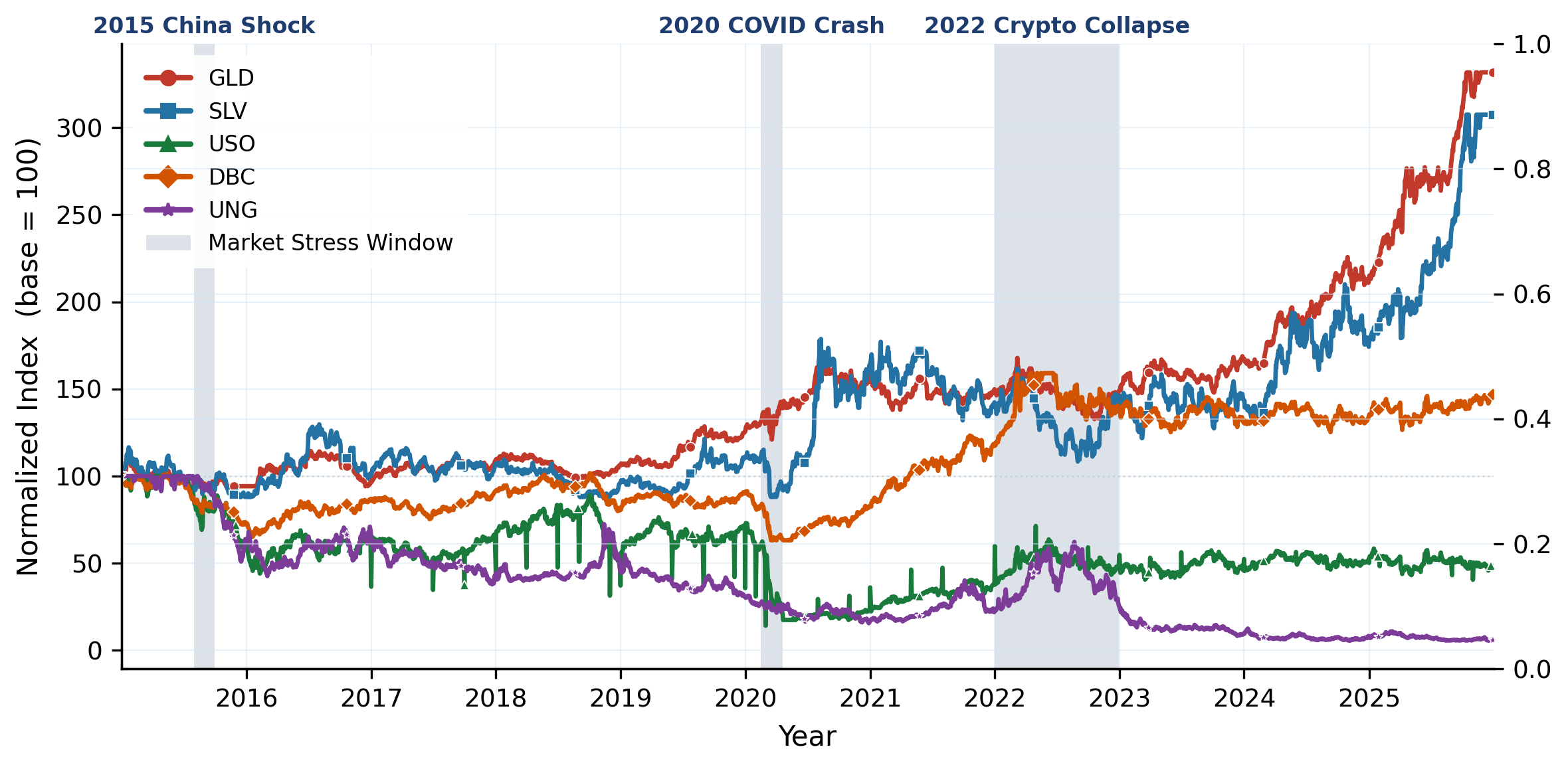
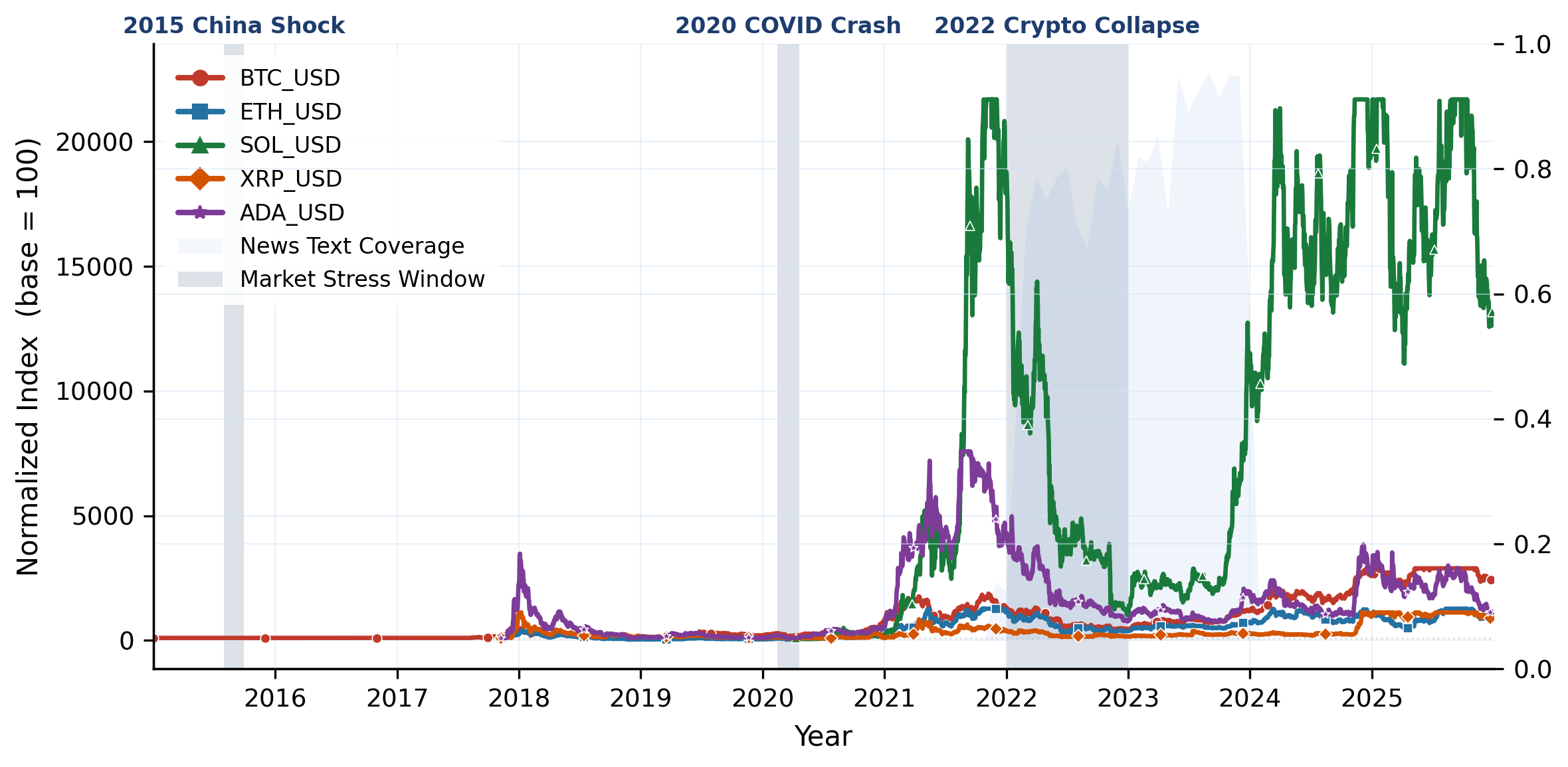
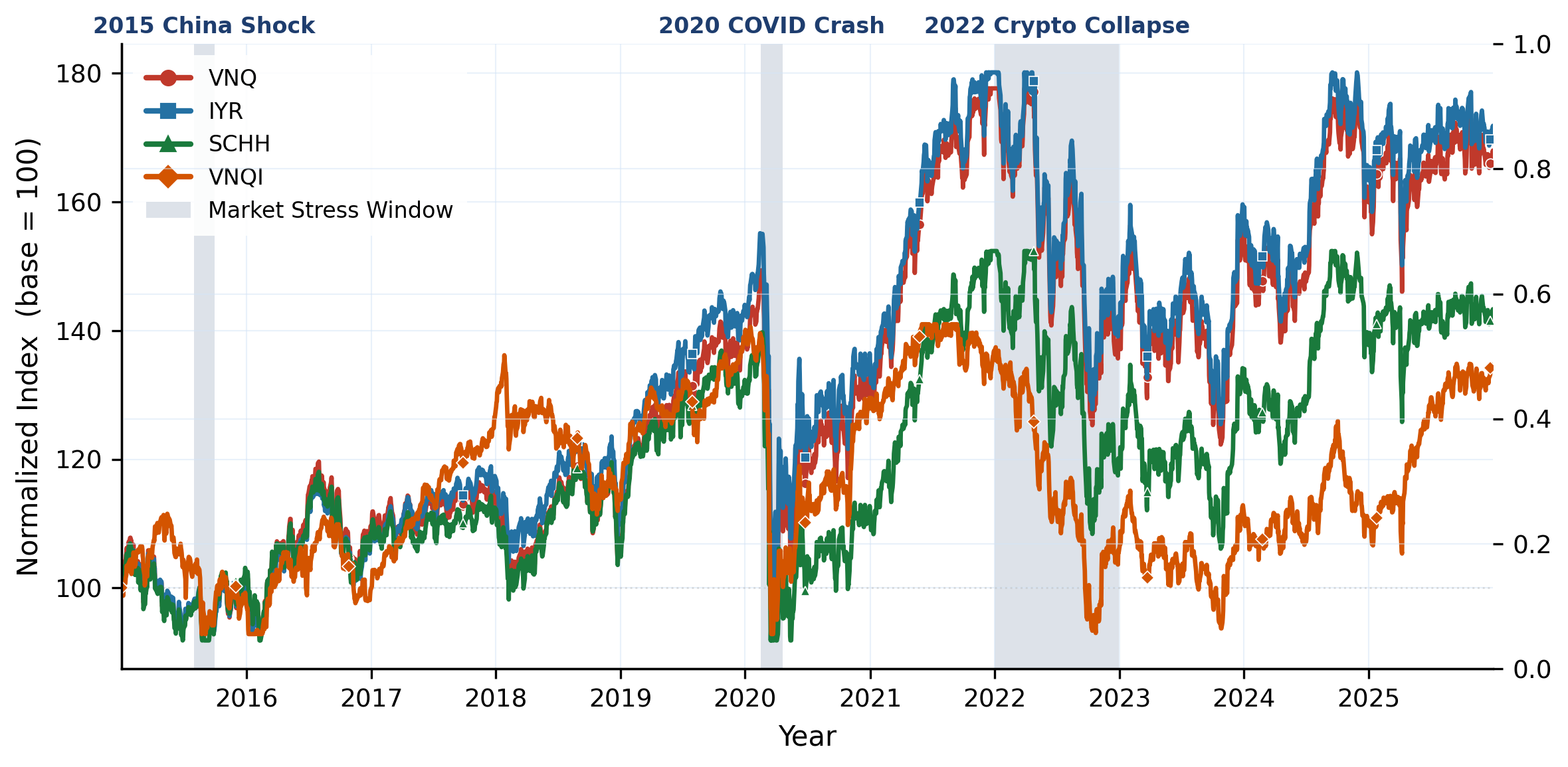
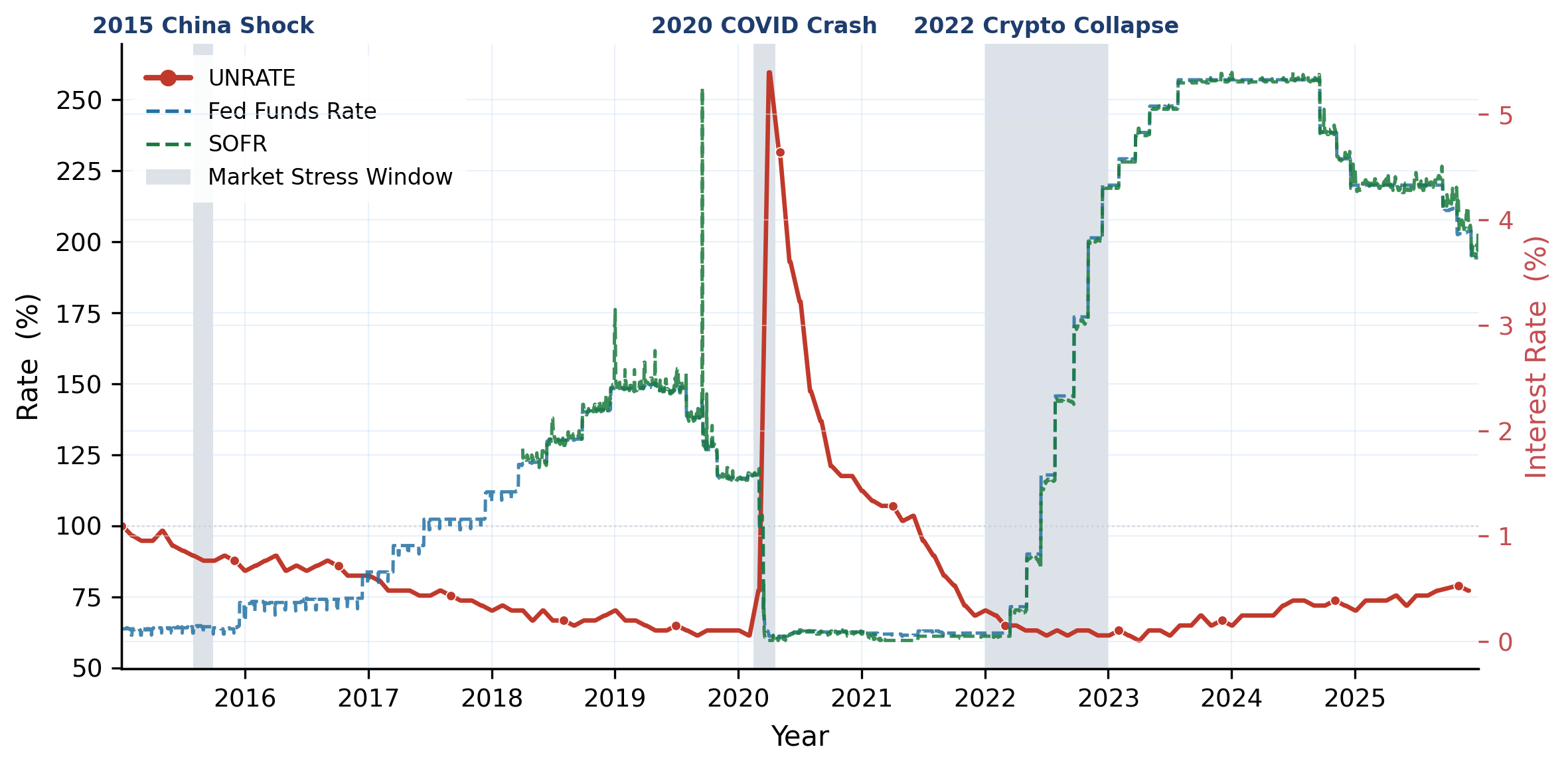
183 instruments across 6 asset classes (equities, bonds, commodities, crypto, real estate, cash) spanning 2015–2025, with daily prices, returns, macro indicators, and news. Inter-class correlations are low, intra-class correlations are high: true diversification means crossing asset-class boundaries, not just picking more tickers.
6,269 correlation-based QA pairs across 7 templates (T1–T7) and 4 difficulty levels, auto-generated from historical data via analytical formulas. Tests correlation reasoning from single-asset prediction to multi-asset constrained allocation to regime-driven rebalancing. Questions and ground truths are derived automatically (no human annotation needed), and new templates can be added on demand.
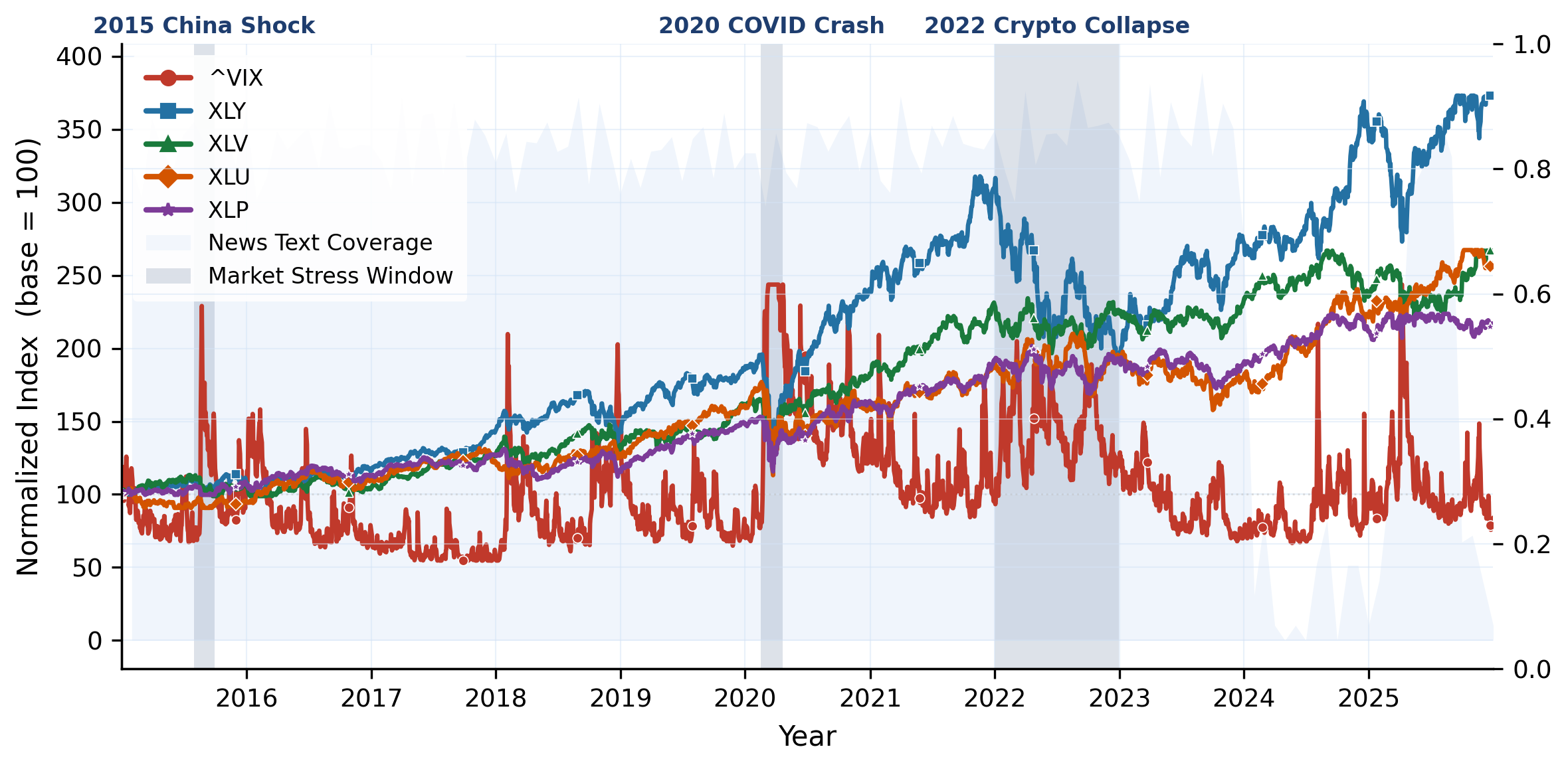
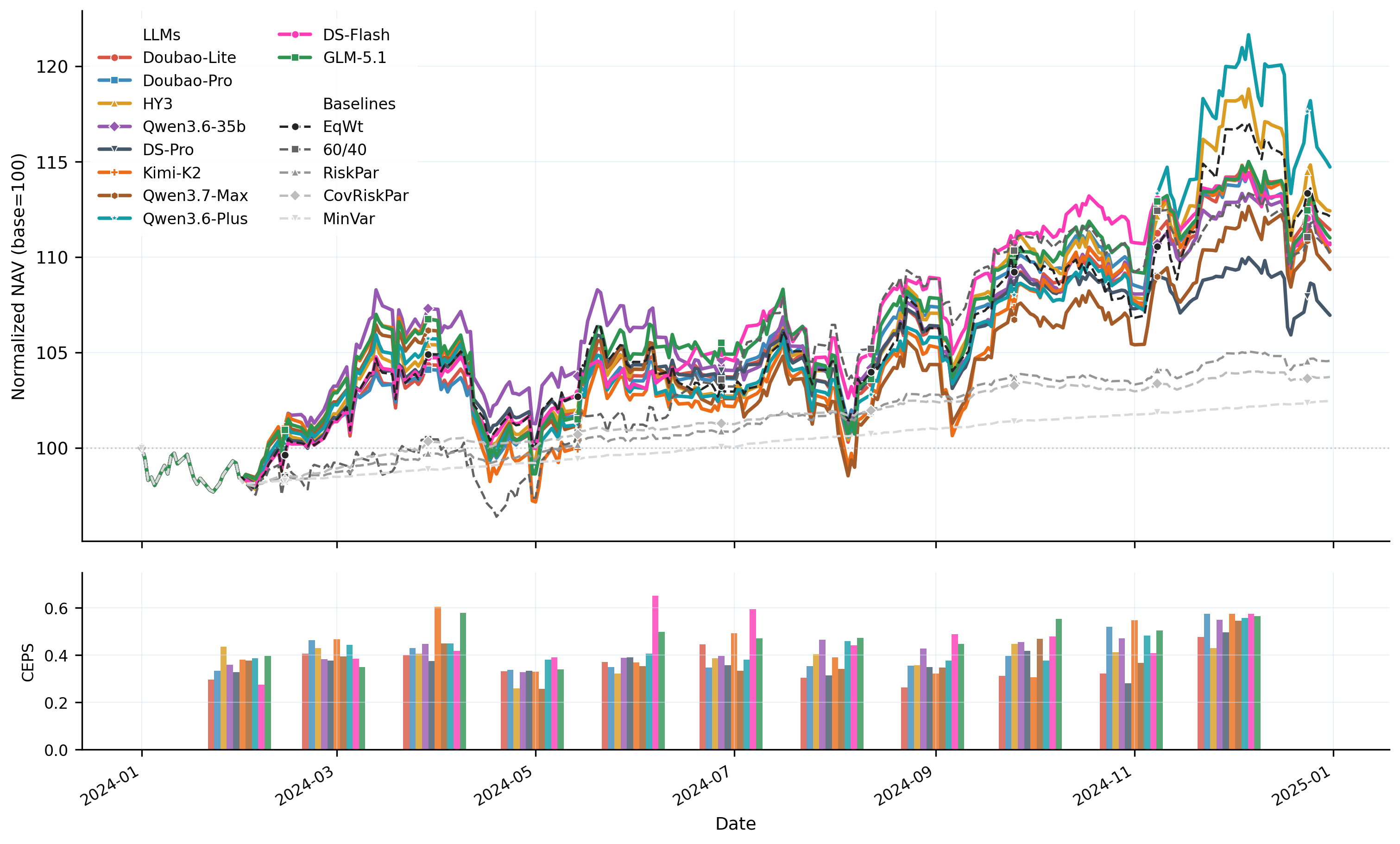
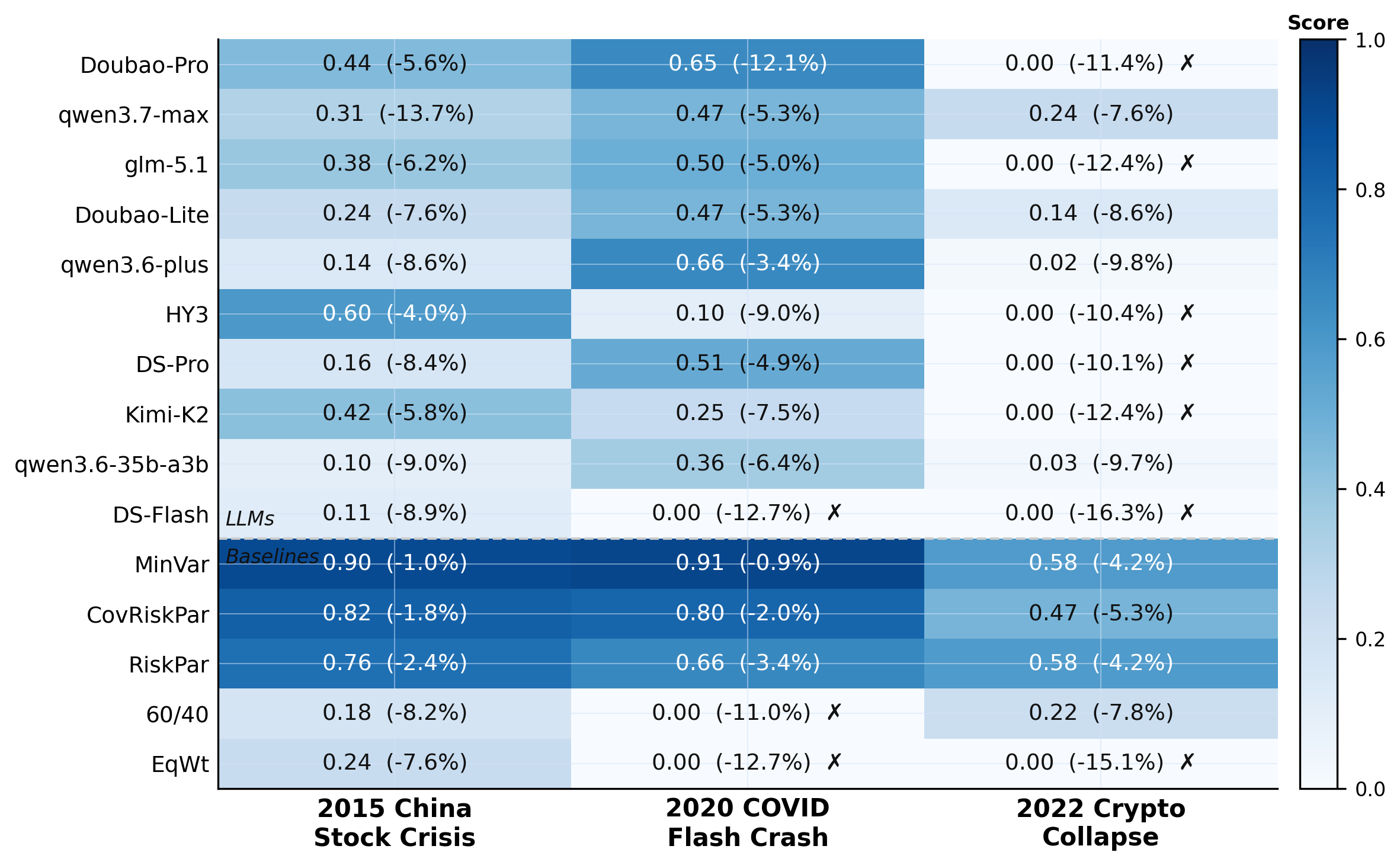
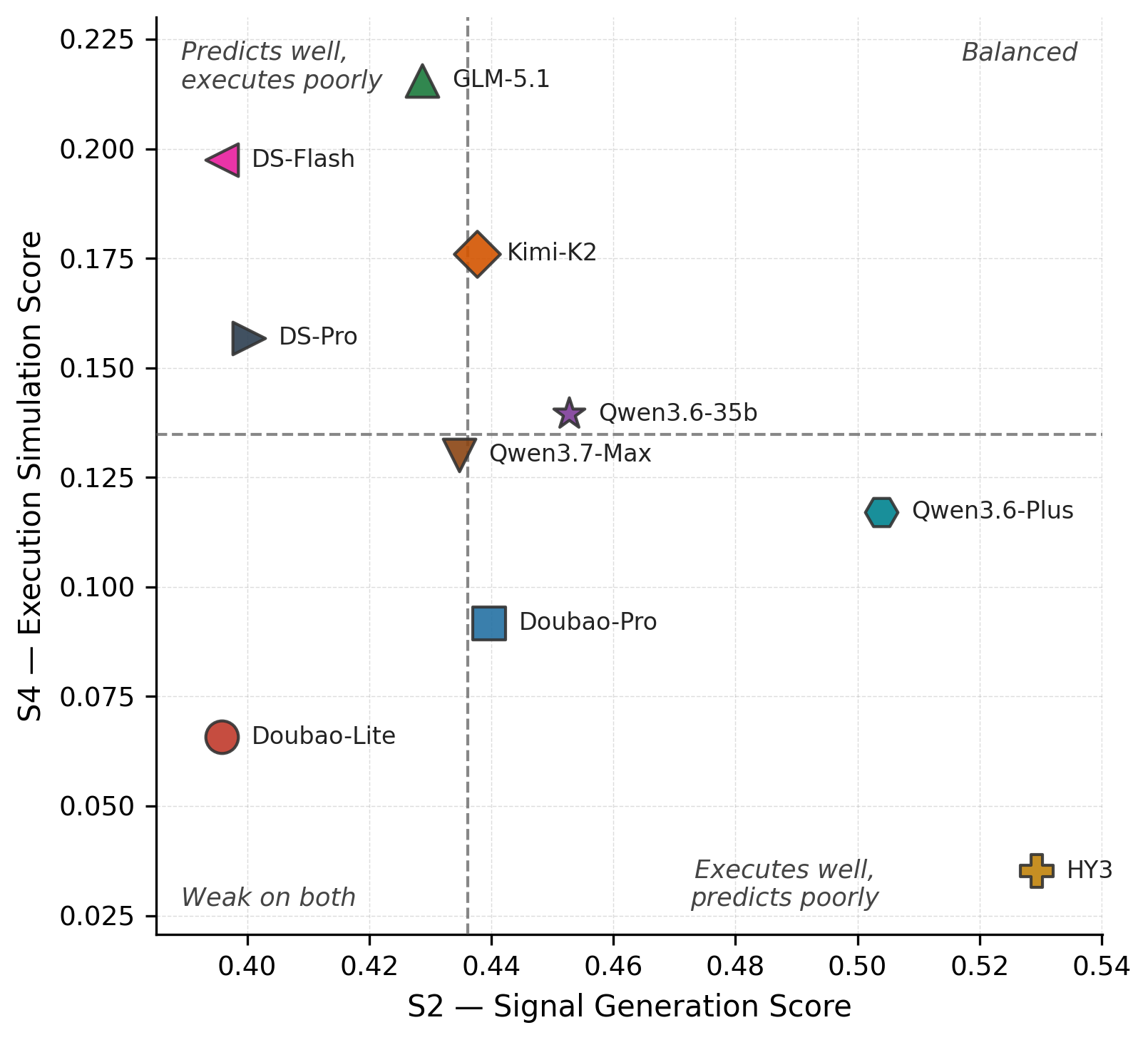
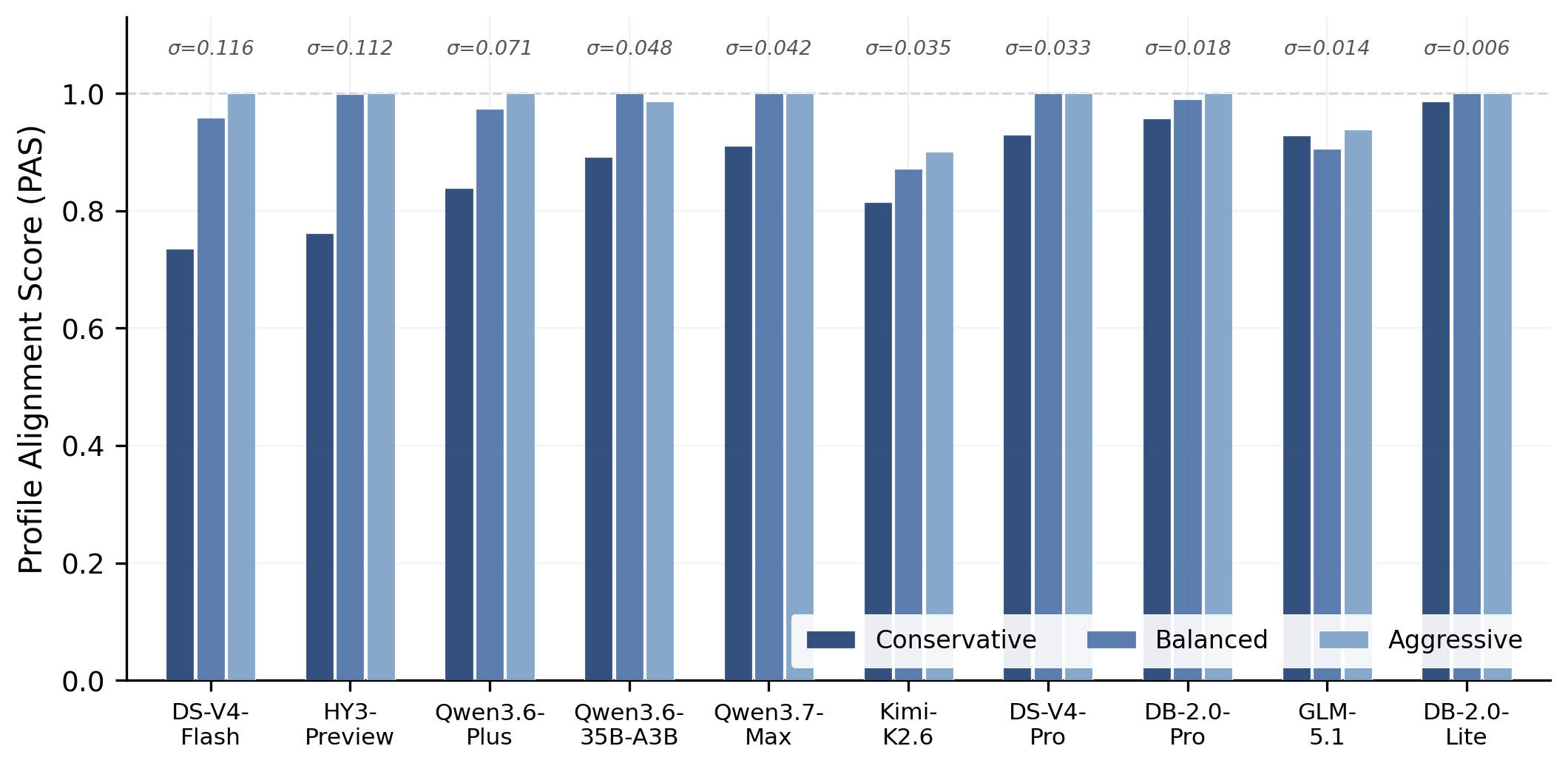
Models execute S1 (Market Interpretation) → S2 (Signal Generation) → S3 (Weight Optimization) → S4 (Execution Simulation) → S5 (Risk Monitoring) sequentially at each rebalance date. A stateful sandbox tracks per-stage scores, weights, and NAV through time to reveal how early errors cascade into final outcomes. Evaluated under 3 investor profiles and 3 historical stress regimes.
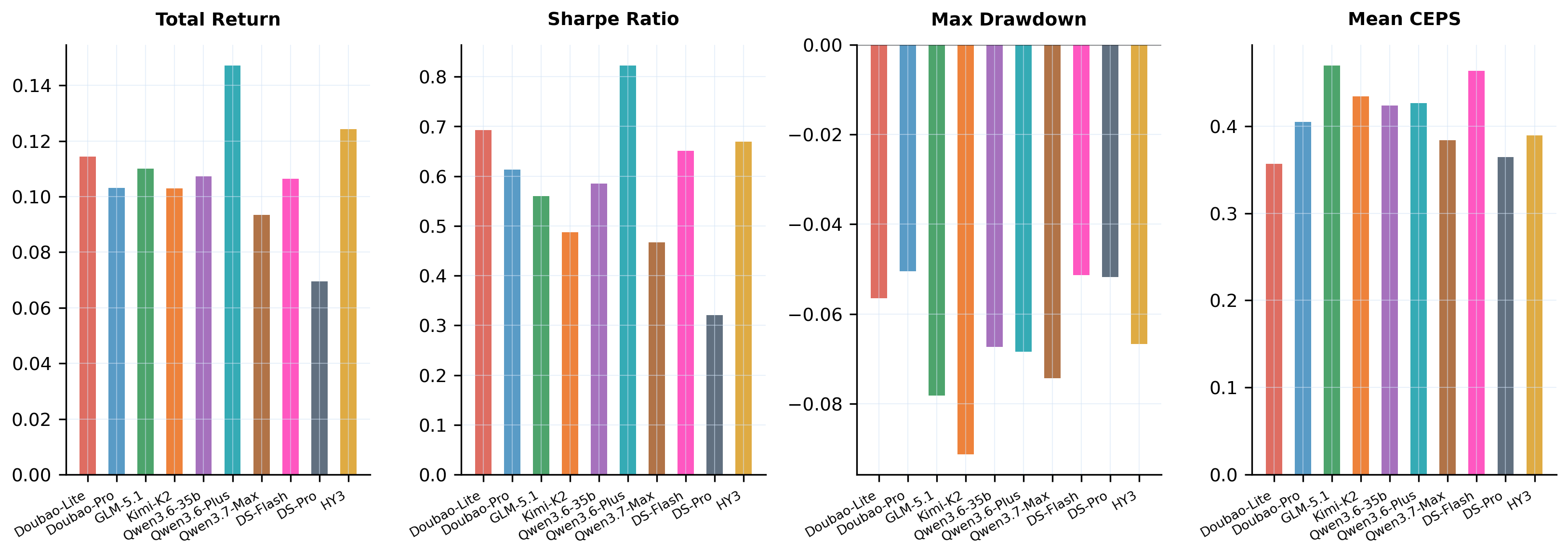
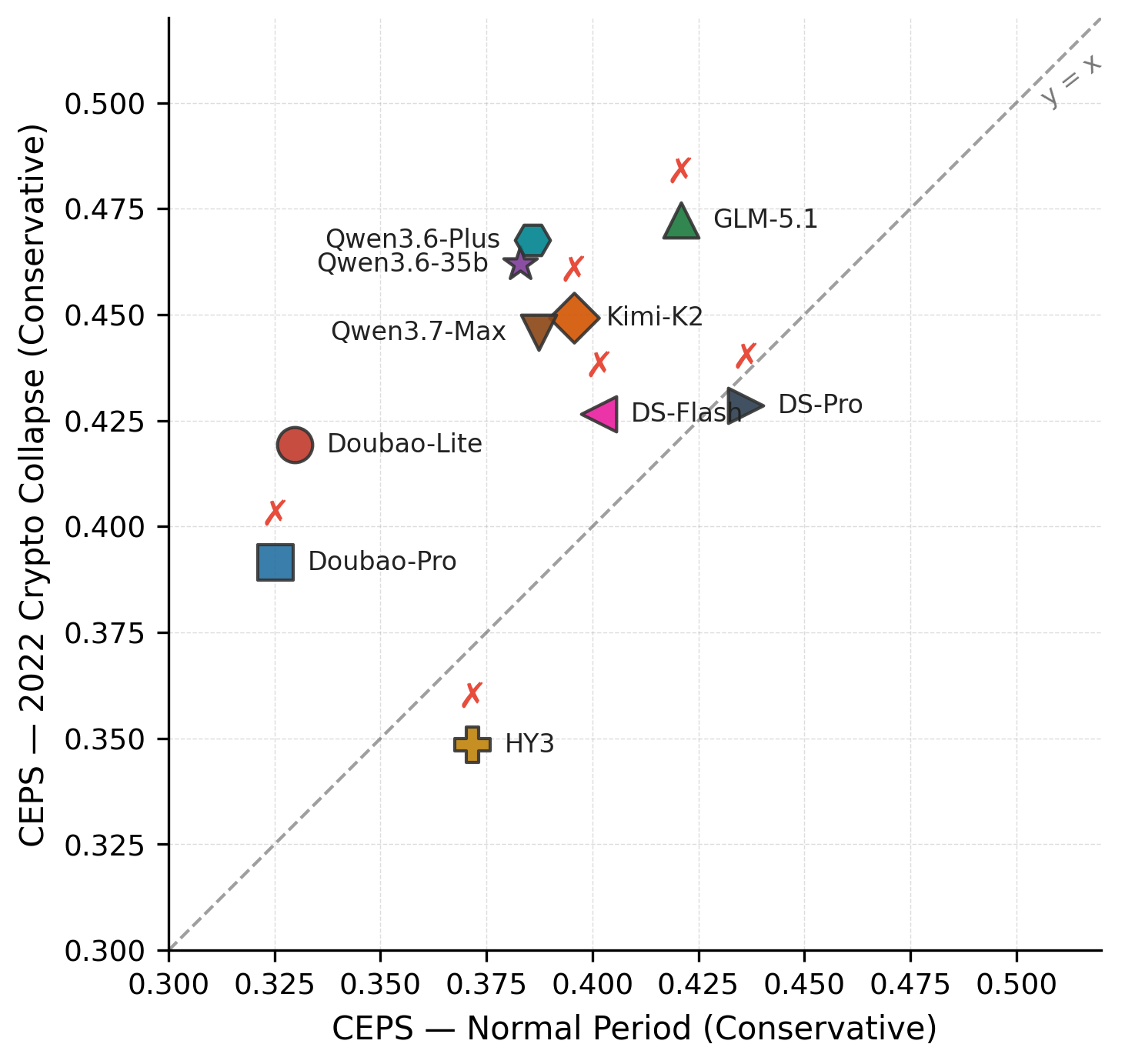
A dual-layer correlation score that measures whether portfolios truly exploit inter-class hedging and avoid intra-class concentration. CEPS, a cross-stage error propagation score, quantifies how reasoning errors compound across pipeline stages: unlike prior benchmarks, CEPS penalizes error cascades rather than averaging scores.
Overview of PortBench. We first collect the Market Base Dataset (183 instruments × 6 asset classes, 2015–2025), then build a dual-layer evaluation framework on top: a static QA layer (6,269 correlation-based pairs) and a dynamic five-stage pipeline, jointly assessed under three risk profiles and three historical stress regimes.
Evaluation framework. Static QA layer (Top): seven task templates generated automatically from historical data. Dynamic five-stage pipeline (Bottom): executed sequentially at every rebalance date under three investor profiles and three stress regimes.